本篇主要是对网上资源的整理,缺乏原创。
什么是SimHash
SimHash是一种局部敏感hash(即Locality Sensitive Hashing,感兴趣可以自行学习下),是google用来处理海量文本去重的算法。
与普通Hash区别
传统的加密式hash,比如md5,其设计的目的是为了让整个分布尽可能地均匀,输入内容哪怕只有轻微变化,hash就会发生很大地变化。
我们理想当中的哈希函数,需要对几乎相同的输入内容,产生相同或者相近的hashcode,换句话说,hashcode的相似程度要能直接反映输入内容的相似程度。很明显,前面所说的md5等传统hash无法满足我们的需求。
假设有以下三段文本:
- the cat sat on the mat
- the cat sat on a mat
- we all scream for ice cream
使用传统hash可能会产生如下的结果:
- the cat sat on the mat -> 415542861
- the cat sat on a mat -> 668720516
- we all scream for ice cream -> 767429688
使用simhash会应该产生类似如下的结果:
- the cat sat on the mat -> 851459198 -> 00110010110000000011110001111110
- the cat sat on a mat -> 847263864 -> 00110010100000000011100001111000
- we all scream for ice crea -> 984968088 -> 00111010101101010110101110011000
可以看到SimHash比传统hash算出来更接近些。
算法原理
simHash值生成过程:
算法过程大概如下:
- 分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程的流程图为: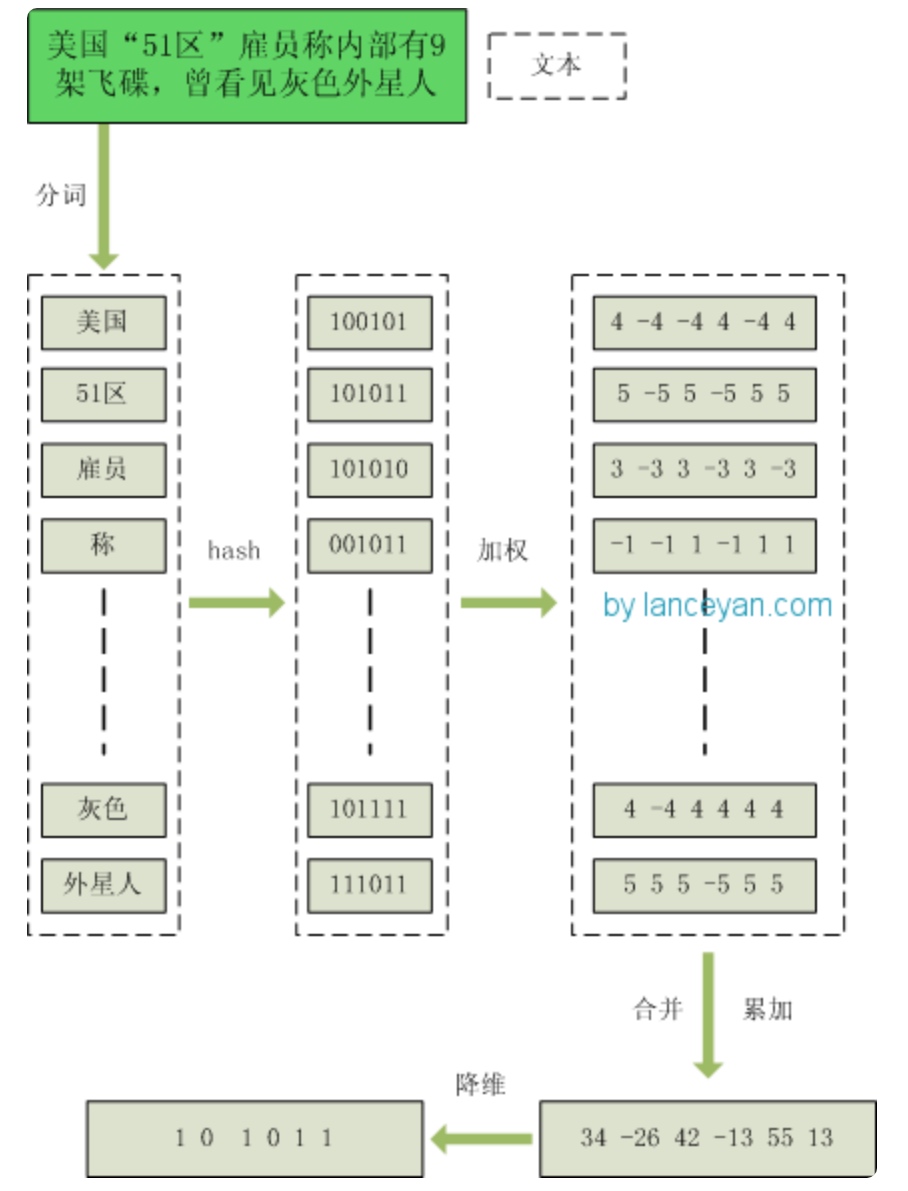
到此,如何从一个doc到一个simhash值的过程已经讲明白了。 但是还有一个重要的部分没讲:海明距离计算。
simhash值的海明距离计算
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
如:1
2
3A = 100111;
B = 101010;
hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3;
当我们算出所有doc的simhash值之后,需要计算doc A和doc B之间是否相似的条件是:
A和B的海明距离是否小于等于n,这个n值根据经验一般取值为3。
海量数据计算海明距离
计算文本相似度问题就转变为-> 有10亿个不重复的64位的01字符串,任意给出一个64位的01字符串f,如何快速从中找出与f汉明距离小于3的字符串?
方法1:前0位上精确匹配,那就要在后面,也就是比较所有
方法2:前61位上精确匹配,后面就不需要比较了
那么折中的想法是 前d bits相同,留下3 bit在(64-d)bit小范围搜索,可行否?
d bits的表示范围有2^d,总量N个指纹,平均每个范围只有N/(2^d)个指纹。
快速定位到前缀是d的位置以后,直接比较范围内N/(2^d)个指纹即可。
假设我们要寻找海明距离3以内的数值,根据鸽巢原理,只要我们将整个64位的二进制串划分为4块,无论如何,匹配的两个simhash code之间至少有一块区域是完全相同的,如下图所示: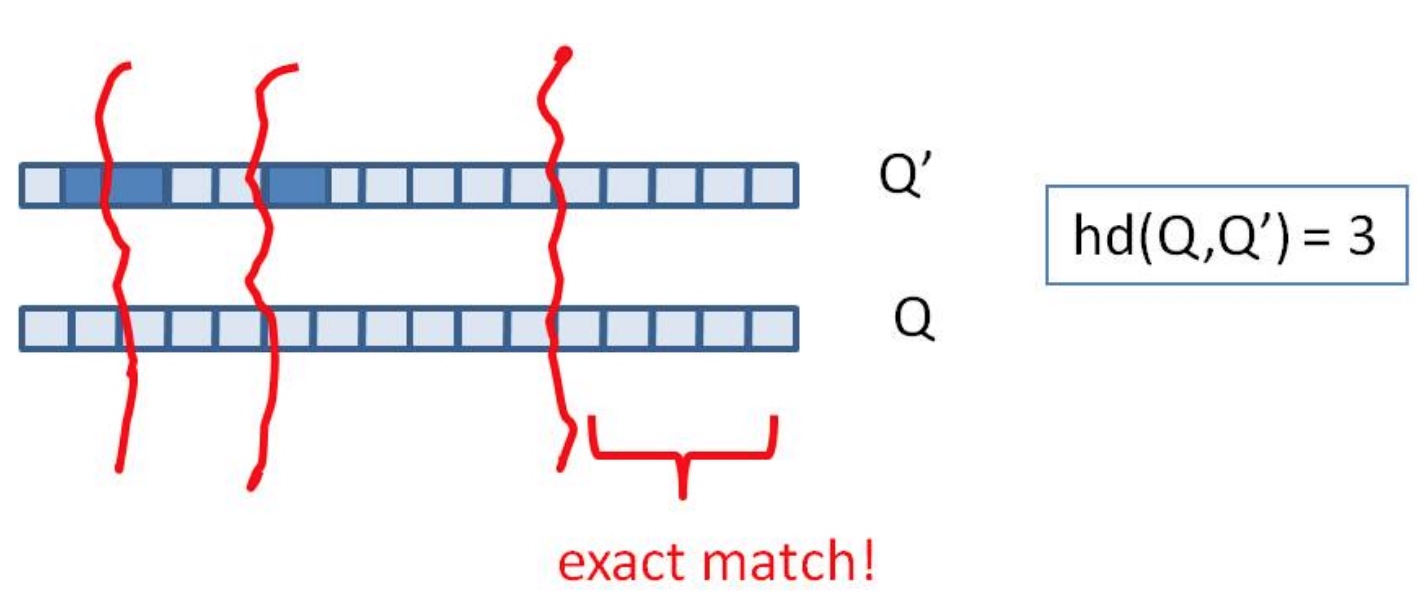
由于我们无法事先得知完全相同的是哪一块区域,因此我们必须采用存储多份table的方式。在本例的情况下,我们需要存储4份table,并将64位的simhash code等分成4份;对于每一个输入的code,我们通过精确匹配的方式,查找前16位相同的记录作为候选记录,如下图所示:
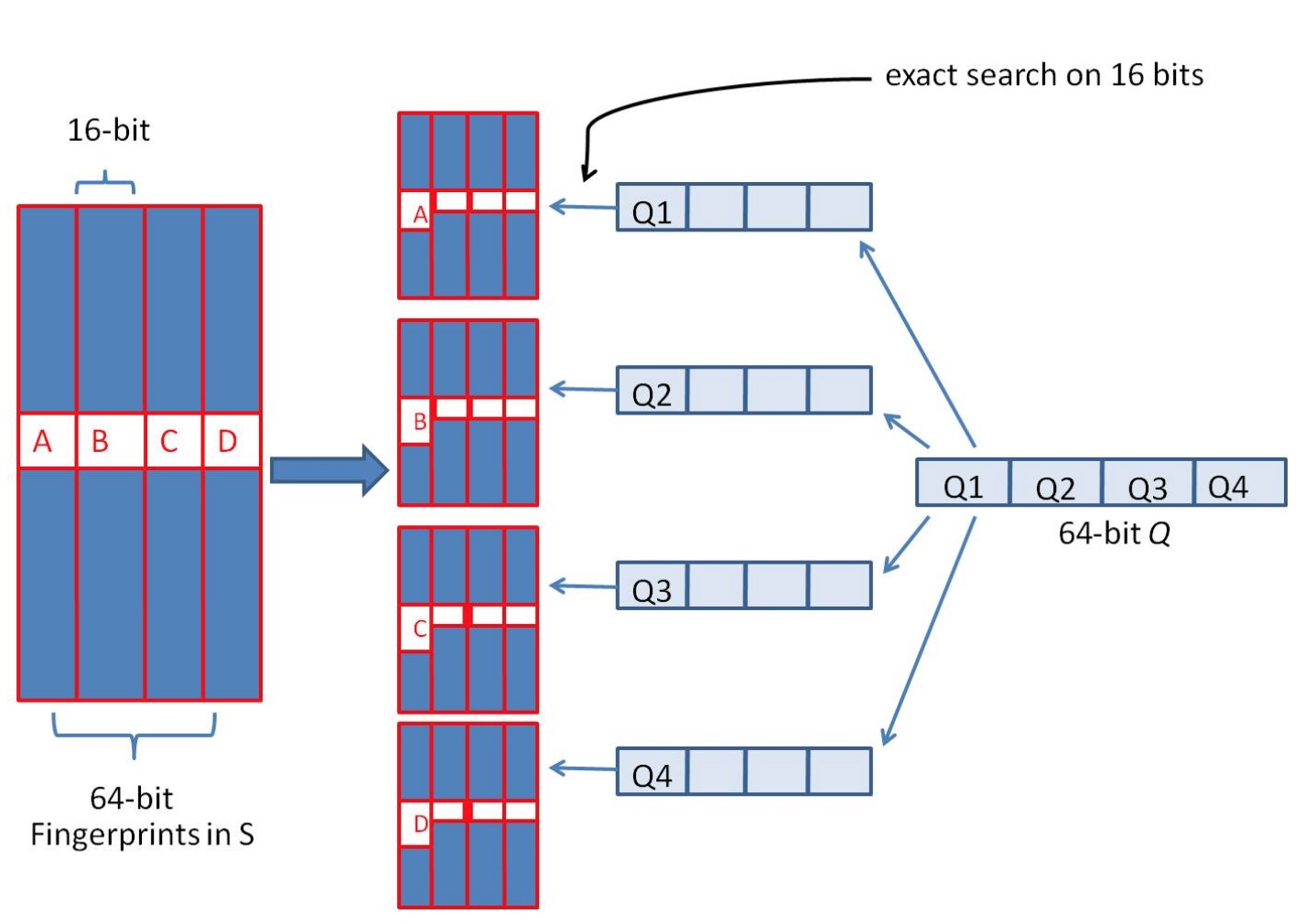
算法过程为:
- 将64位的二进制串等分成四块
- 调整上述64位二进制,将任意一块作为前16位,总共有四种组合,即每个指纹生成4个指纹。
- 采用精确匹配的方式查找前16位
- 如果样本库中存有2^30(差不多10亿)的哈希指纹,每个指纹存四份即 2^30 * 2^2 = 2^32个哈希指纹。共有2^16种类型,每种类型有 2^32 / 2^16 = 65536 个候选结果,大大减少了海明距离的计算成本。
与其他算法对比
- 百度的去重算法
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。 - shingle算法
shingle原理略复杂,对于工程实现不够友好,速度太慢,基本上无法处理海量数据。
