概述
RAFT协议作用是保证分布式系统同一数据的一致性(与2pc不同,2pc是保证多个数据的原子性)。
采取的方式是分布式系统中只有一个节点接收数据,然后向其他节点复制
在一个由 Raft 协议组织的集群中有三类角色:
- Leader(领袖)
- Follower(群众)
- Candidate(候选人)
Raft将问题分解和具体化:Leader统一处理变更操作请求,一致性协议的作用具化为保证节点间操作日志副本(log replication)一致,以term作为逻辑时钟(logical clock)保证时序,节点运行相同状态机(state machine)得到一致结果。Raft协议具体过程如下:
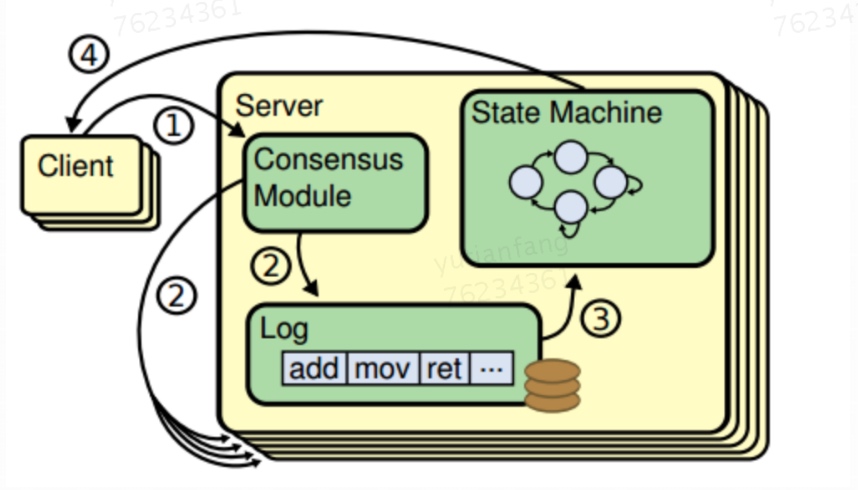
- Client发起请求,每一条请求包含操作指令
- 请求交由Leader处理,Leader将操作指令(entry)追加(append)至操作日志,紧接着对Follower发起AppendEntries请求、尝试让操作日志副本在Follower落地
- 如果Follower多数派(quorum)同意AppendEntries请求,Leader进行commit操作、把指令交由状态机处理
- 状态机处理完成后将结果返回给Client
指令通过log index(指令id)和term number保证时序,正常情况下Leader、Follower状态机按相同顺序执行指令,得出相同结果、状态一致。
宕机、网络分化等情况可引起Leader重新选举(每次选举产生新Leader的同时,产生新的term)、Leader/Follower间状态不一致。Raft中Leader为自己和所有Follower各维护一个nextIndex值,其表示Leader紧接下来要处理的指令id以及将要发给Follower的指令id,LnextIndex不等于FnextIndex时代表Leader操作日志和Follower操作日志存在不一致,这时将从Follower操作日志中最初不一致的地方开始,由Leader操作日志覆盖Follower,直到LnextIndex、FnextIndex相等。
Paxos中Leader的存在是为了提升决议效率,Leader的有无和数目并不影响决议一致性,Raft要求具备唯一Leader,并把一致性问题具体化为保持日志副本的一致性,以此实现相较Paxos而言更容易理解、更容易实现的目标。
RAFT论文
论文讲的很详细了
一个简单的例子
动画方式展示原理
相比于Paxos,Raft最大的特点就是可理解性。
Raft把一致性问题,分解成三个比较独立的子问题,并给出每个子问题的解决方法。
选举
当现存的领导人不存在时,需要选举新的领导人。
任期(term)
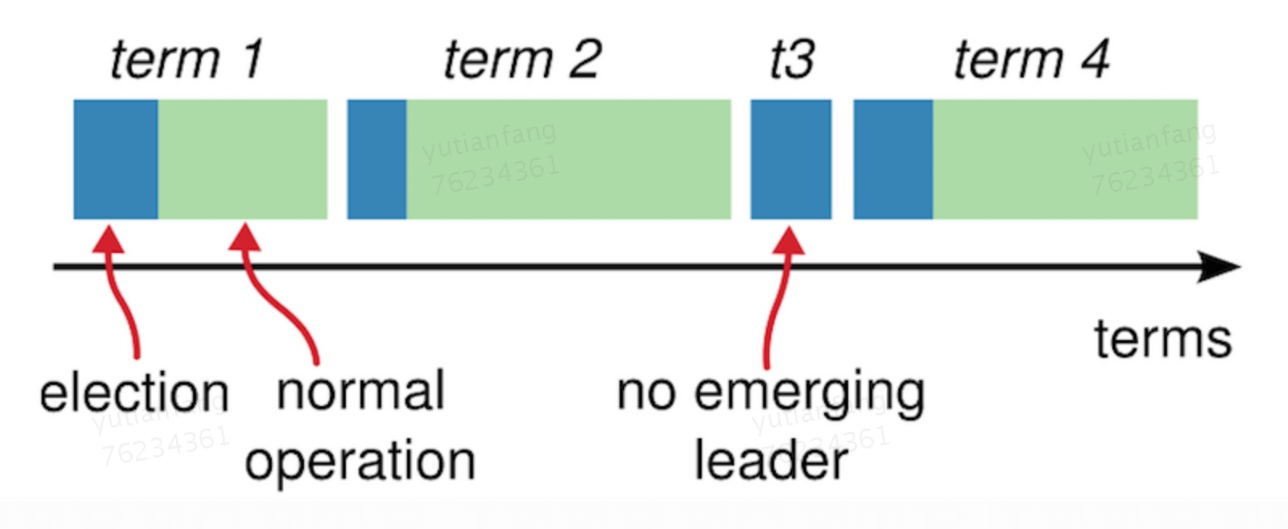
Raft 算法将时间划分成为任意不同长度的任期(term)。任期用连续的数字进行表示。
每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。每次选举任期号都增加。
如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。
在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。
Raft 算法保证在给定的一个任期最多只有一个领导人。
触发条件
- 一般情况下,追随者接到领导者的心跳时,把ElectionTimeout(后面会讲election timeout)清零,不会触发;
- 领导者故障,追随者的ElectionTimeout超时发生时,会变成候选者,触发领导人选取
选举过程
- 每个节点以follower启动。
- 每个节点设置一个150-300ms的随机超时时间(election timeout),没有接收到leader消息时,变成candinate。
- candinate要求其他节点投票。
- 各节点投票。
- 如果超过半数投票,candinate变成leader。
有两个超时时间控制选举过程。
election timeout
- follower等待这个时间,超过这个时间变为candinate,发起新的选举。
- 如果其他follower在该任期内没投过票,就会给发起投票的candinate投票。并重置自己的election timeout。
- 超过半数投票,candinate变为leader
- leader开始向followers发送Append Entries(包含心跳信息及日志)消息。
heartbeat timeout
- leader 必须在 heartbeat timeout 间隔内发送Append Entries消息。
- follower会响应每个Append Entries消息,重置自己的election timeout。
- 在follower停止接收heartbeats并且成为candinate时,停止选举过程
日志复制
描述Raft的leader是如何把日志复制到集群的各个节点上的。
领导人必须从客户端接收日志然后复制到集群中的其他节点,并且强制要求其他节点的日志保持和自己相同。
日志复制过程
- 客户端请求只经过leader。
- 每个变化都作为entry加到leader日志中。
- log entry是uncomitted状态,所以不会更新节点值。
- 将日志同步到follower节点,完成更新节点值。
- leader等待超过半数follower更新成功。
- leader entry状态变为commited。
- leader通知entry状态为commited。
- 响应客户端。
安全性
| 特性 | 解释 |
|---|---|
| 日志匹配原则 | 如果两个日志在相同的索引位置的日志条目的任期号相同,那么我们就认为这个日志从头到这个索引位置之间全部完全相同(5.3 log replication 节)if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index. |
| 状态机安全特性 | 如果一个领导人已经在给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会提交一个不同的日志(5.4.3 安全性论证 节)if a server has applied a particular log entry to its state machine, then no other server may apply a different command for the same log. |
| 选举安全特性 | 对于一个给定的任期号,最多只会有一个领导人被选举出来(5.2 leader election 节)at most one leader can be elected in a given term. |
| 领导人只附加原则 | 领导人绝对不会删除或者覆盖自己的日志,只会增加(5.3 log replication 节)a leader can only append new entries to its logs (it can neither overwrite nor delete entries). |
| 领导人完全特性 | 如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中(5.4 安全性 节)if a log entry is committed in a given term then it will be present in the logs of the leaders since this term |
一个跟随者可能会进入不可用状态同时领导人已经提交了若干的日志条目,然后这个跟随者可能会被选举为领导人并且覆盖这些日志条目;因此,不同的状态机可能会执行不同的指令序列。
这一节通过在领导选举的时候增加一些限制来完善 Raft 算法。这一限制保证了任何的领导人对于给定的任期号,都拥有了之前任期的所有被提交的日志条目。
增加这一选举时的限制,我们对于提交时的规则也更加清晰。
Raft 保证,只有包含了所有已经提交的日志条目的候选人才有可能赢得选举。
候选人为了赢得选举必须联系集群中的大部分节点,这意味着每一个已经提交的日志条目在这些服务器节点中肯定存在于至少一个节点上。
如果候选人的日志至少和大多数的服务器节点一样新(这个新的定义会在下面讨论),那么他一定持有了所有已经提交的日志条目。
请求投票 RPC 实现了这样的限制: RPC 中包含了候选人的日志信息,然后投票人会拒绝掉那些日志没有自己新的投票请求。
Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新:
- 如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。
- 如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。
**Raft 永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目。只有领导人当前任期里的日志条目通过计算副本数目可以被提交;
一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。(Leader可以复制前面任期的日志,但是不会主动提交前面任期的日志。而是通过提交当前任期的日志,而间接地提交前面任期的日志)
在某些情况下,领导人可以安全的知道一个老的日志条目是否已经被提交(例如,该条目是否存储到所有服务器上),但是 Raft 为了简化问题使用一种更加保守的方法。
当领导人复制之前任期里的日志时,Raft 会为所有日志保留原始的任期号, 这在提交规则上产生了额外的复杂性。在其他的一致性算法中,如果一个新的领导人要重新复制之前的任期里的日志时,它必须使用当前新的任期号。Raft 使用的方法更加容易辨别出日志,因为它可以随着时间和日志的变化对日志维护着同一个任期编号。另外,和其他的算法相比,Raft 中的新领导人只需要发送更少日志条目(其他算法中必须在他们被提交之前发送更多的冗余日志条目来为他们重新编号).**
为了消除上述场景就规定Leader可以复制前面任期的日志,但是不会主动提交前面任期的日志。而是通过提交当前任期的日志,而间接地提交前面任期的日志。
时间和可用性
Raft 的要求之一就是安全性不能依赖时间:整个系统不能因为某些事件运行的比预期快一点或者慢一点就产生了错误的结果。但是,可用性(系统可以及时的响应客户端)不可避免的要依赖于时间。例如,如果消息交换在服务器崩溃时花费更多的时间,候选人将不会等待太长的时间来赢得选举;没有一个稳定的领导人,Raft 将无法工作。
领导人选举是 Raft 中对时间要求最为关键的方面。Raft 可以选举并维持一个稳定的领导人,只要系统满足下面的时间要求:
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)
在这个不等式中,广播时间指的是从一个服务器并行的发送 RPCs 给集群中的其他服务器并接收响应的平均时间;
选举超时时间就是在 5.2 节中介绍的选举的超时时间限制;
然后平均故障间隔时间就是对于一台服务器而言,两次故障之间的平均时间。
广播时间必须比选举超时时间小一个量级,这样领导人才能够发送稳定的心跳消息来阻止跟随者开始进入选举状态;通过随机化选举超时时间的方法,这个不等式也使得选票瓜分的情况变得不可能。
选举超时时间应该要比平均故障间隔时间小上几个数量级,这样整个系统才能稳定的运行。当领导人崩溃后,整个系统会大约相当于选举超时的时间里不可用;我们希望这种情况在整个系统的运行中很少出现。
广播时间和平均故障间隔时间是由系统决定的,但是选举超时时间是我们自己选择的。Raft 的 RPCs 需要接收方将信息持久化的保存到稳定存储中去,所以广播时间大约是 0.5 毫秒到 20 毫秒,取决于存储的技术。因此,选举超时时间可能需要在 10 毫秒到 500 毫秒之间。大多数的服务器的平均故障间隔时间都在几个月甚至更长,很容易满足时间的需求。
应用
- ETCD
- 百度云 braft
