介绍下比较好用的zsh安装以及相关的配置
RabbitMQ概述
安装
mac上安装rabbitmq比较简单,参考官网教程 http://www.rabbitmq.com/install-standalone-mac.html 即可。遇到了下载很慢问题,找了其他网站上下。
其他系统安装方式在官网也有详细描述,不再累述。
spring事务管理
事务是什么
弄清spring事务管理机制,首先要弄清什么是事务。
人们创建了一个术语来表示事务:ACID。ACID代表四个特性,相信大家都很熟悉,但我也要贴出来。
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性:数据库允许多个并发事务同时对齐数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
(以上内容来自维基百科)
但ACID还是太过抽象,事务到底是怎么创建出来的?下面通过具体的代码来描述下。
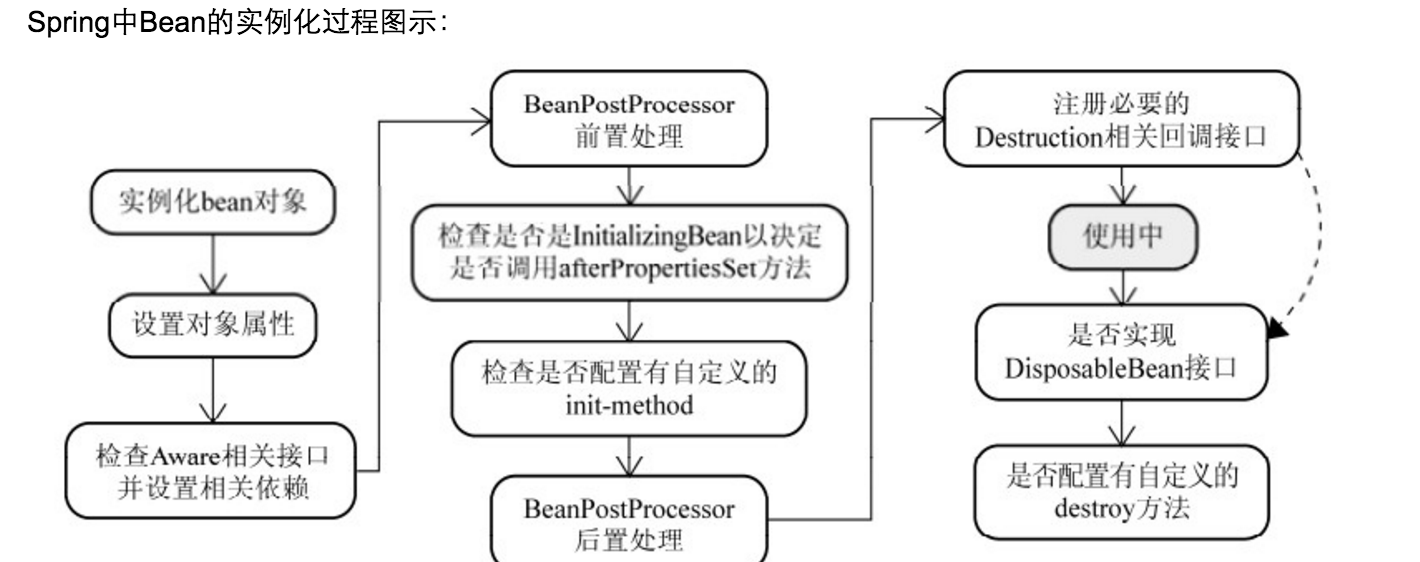
spring bean初始化过程
springmvc 请求处理过程
一个请求到达服务器之后,springmvc处理过程: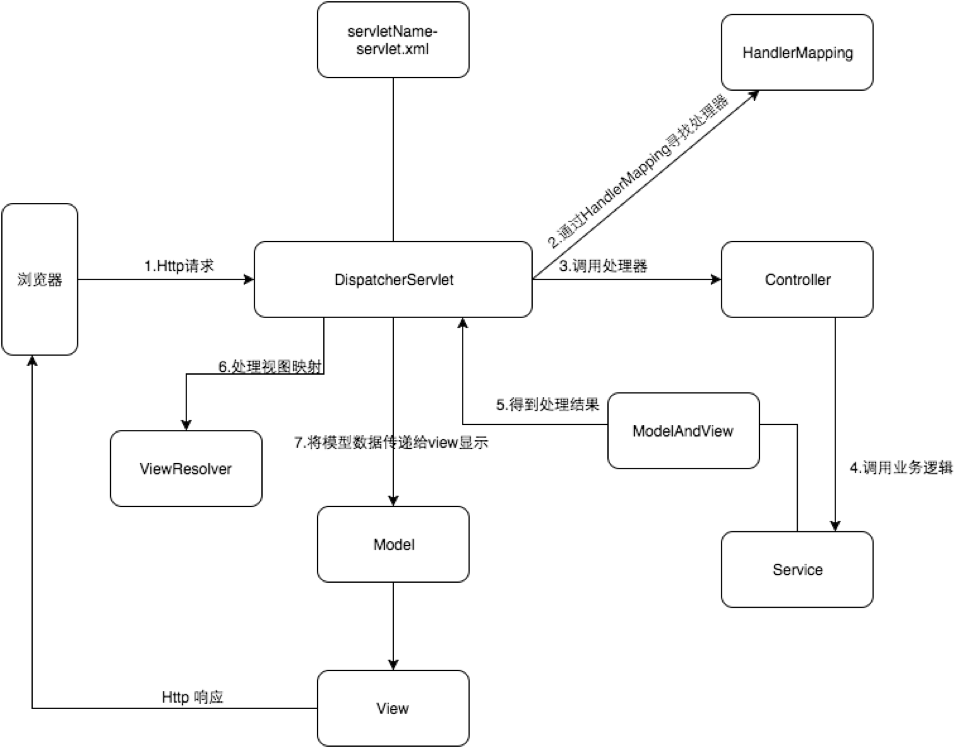
spring 拦截器
处理器拦截器简介
Spring Web MVC的处理器拦截器(如无特殊说明,下文所说的拦截器即处理器拦截器)
类似于Servlet开发中的过滤器Filter,用于对处理器进行预处理和后处理。
常见应用场景
- 日志记录:记录请求信息的日志,以便进行信息监控、信息统计、计算PV(Page View)等。
- 权限检查:如登录检测,进入处理器检测检测是否登录,如果没有直接返回到登录页面;
- 性能监控:有时候系统在某段时间莫名其妙的慢,可以通过拦截器在进入处理器之前记录开始时间,在处理完后记录结束时间,从而得到该请求的处理时间(如果有反向代理,如apache可以自动记录);
- 通用行为:读取cookie得到用户信息并将用户对象放入请求,从而方便后续流程使用,还有如提取Locale、Theme信息等,只要是多个处理器都需要的即可使用拦截器实现。
- OpenSessionInView:如Hibernate,在进入处理器打开Session,在完成后关闭Session。
…………本质也是AOP(面向切面编程),也就是说符合横切关注点的所有功能都可以放入拦截器实现。